WANDR is the first human motion generation model that is driven by an active feedback loop learned purely from data,
without any extra steps of reinforcement learning (RL).
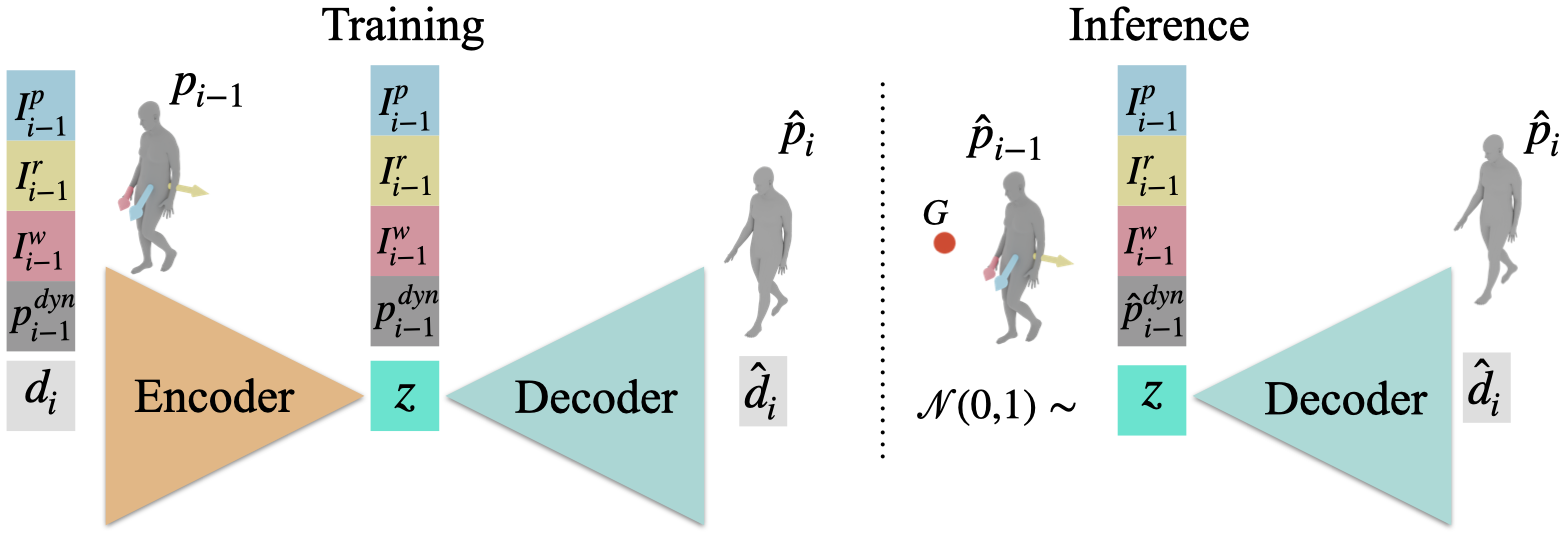
WANDR generates motion autoregressively (frame-by-frame). At each step, it predicts a state-delta that will progress the human to the next state.
The prediction of the state-delta is conditioned on time- and goal-dependent features that we call "intention" (visualized as arrows in videos below).
These features are computed at every frame and act as a feedback loop that guides the motion generation to reach the goal. For more details on the intention, please refer to section 3.2 of the paper.
Existing datasets that capture motion of humans reaching for goals, like
CIRCLE, are scarce have very small scale to enable generalization.
This is why
RL is a popular approach to learn similar tasks. However, RL comes with its own set of challenges such as sample complexity.
Inspired by the paradigm of behavioral cloning we propose a purely data-driven approach where during training a future position of the avatar's hand is considered as the goal. By hallucinating goals this way, we are able to combine
both smaller datasets with goal annotations such as
CIRCLE,
as well as large scale like
AMASS that have no goal labels but are essential to learning general navigational skills such as walking, turning etc.